Abstract
Two!Ears replaces current thinking about auditory modeling by a systemic approach in which human listeners are regarded as multi-modal agents that develop their concept of the world by exploratory interaction. The goal of the project is to develop an intelligent, active computational model of auditory perception and experience in a multi-modal context. Our novel approach is based on a structural link from binaural perception to judgment and action, realized by interleaved signal-driven (bottom-up) and hypothesis-driven (top-down) processing within an innovative expert-system architecture. The system achieves object formation based on Gestalt principles, meaning assignment, knowledge acquisition and representation, learning, logic-based reasoning and reference-based judgment. More specifically, the system assigns meaning to acoustic events by combining signal- and symbol-based processing in a joint model structure, integrated with proprioceptive and visual percepts. It is therefore able to describe an acoustic scene in much the same way that a human listener and in terms of the sensations that sounds evoke (e.g. loudness, timbre, spatial extent) and their semantics (e.g., whether the sound is unexpected or a familiar voice). Our system will be implemented on a robotic platform, which will actively parse its physical environment, orientate itself and move its sensors in a humanoid manner. The system has an open architecture, so that it can easily be modified or extended. This is crucial, since the cognitive functions to be modeled are domain and application specific. Two!Ears will have significant impact on future development of ICT wherever knowledge and control of aural experience is relevant. It will also benefit research in related areas such as biology, medicine and sensory and cognitive psychology.
Objective
The objective of the Two!Ears project can best be derived from the architecture of the various modules and the flow of information between them.
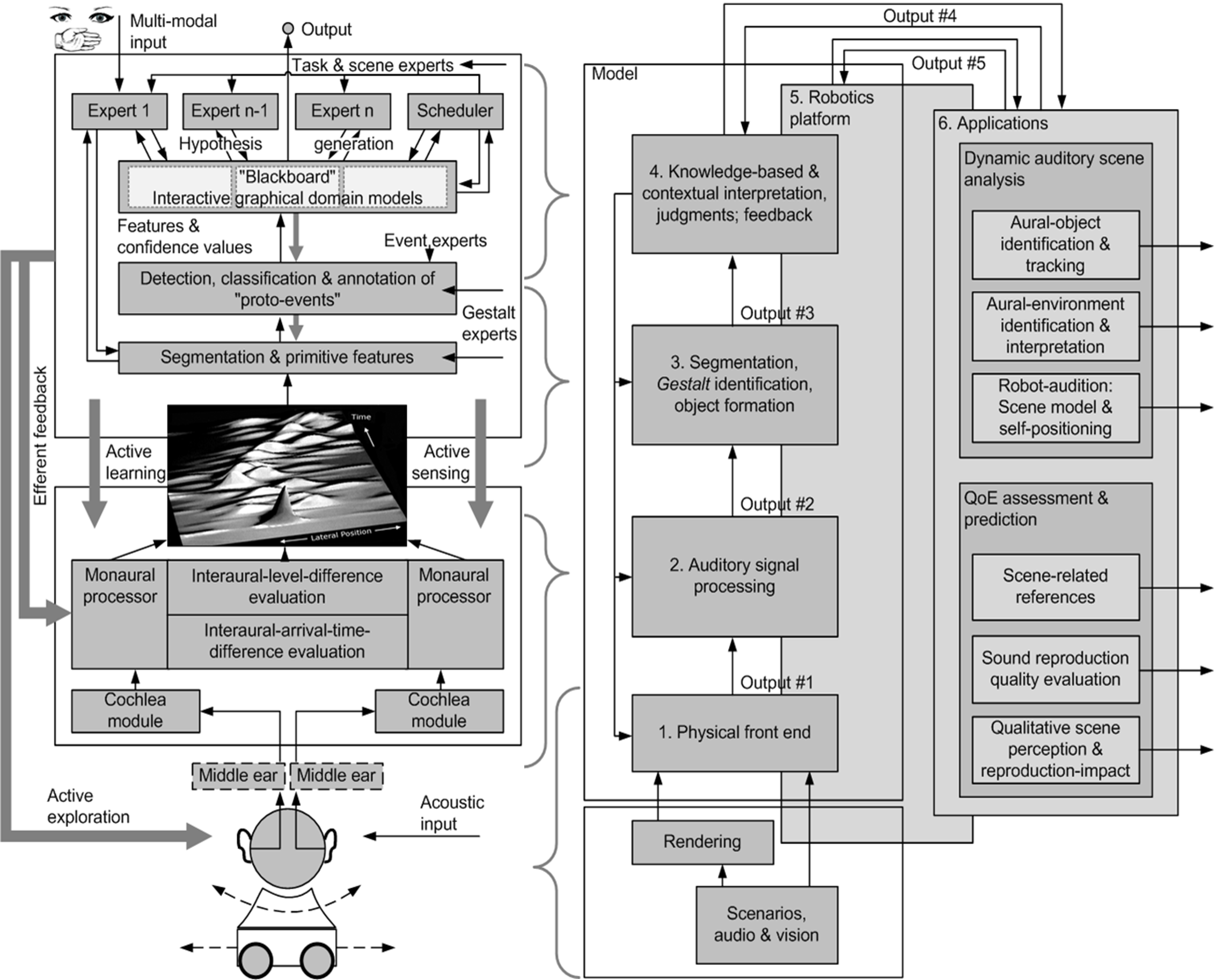
Architecture of the Two!Ears project. Left panel: Flow graph that illustrates the degree of detail in current discussions within the consortium. Two kinds of feedback are differentiated in the figure: low-level feedback akin to reflexive circuits and feedback from higher-level processing triggered by hypotheses in the blackboard system. Right panel: Diagram of the main functional blocks of Two!Ears, also referring to the technical work packages.
Work Plan
The project activities are organized in 8 different work packages. Six of them (WP1-WP6) are technical work packages which are accompanied by WP 7 Dissemination, collaboration and exploitation and by the Management WP 8.
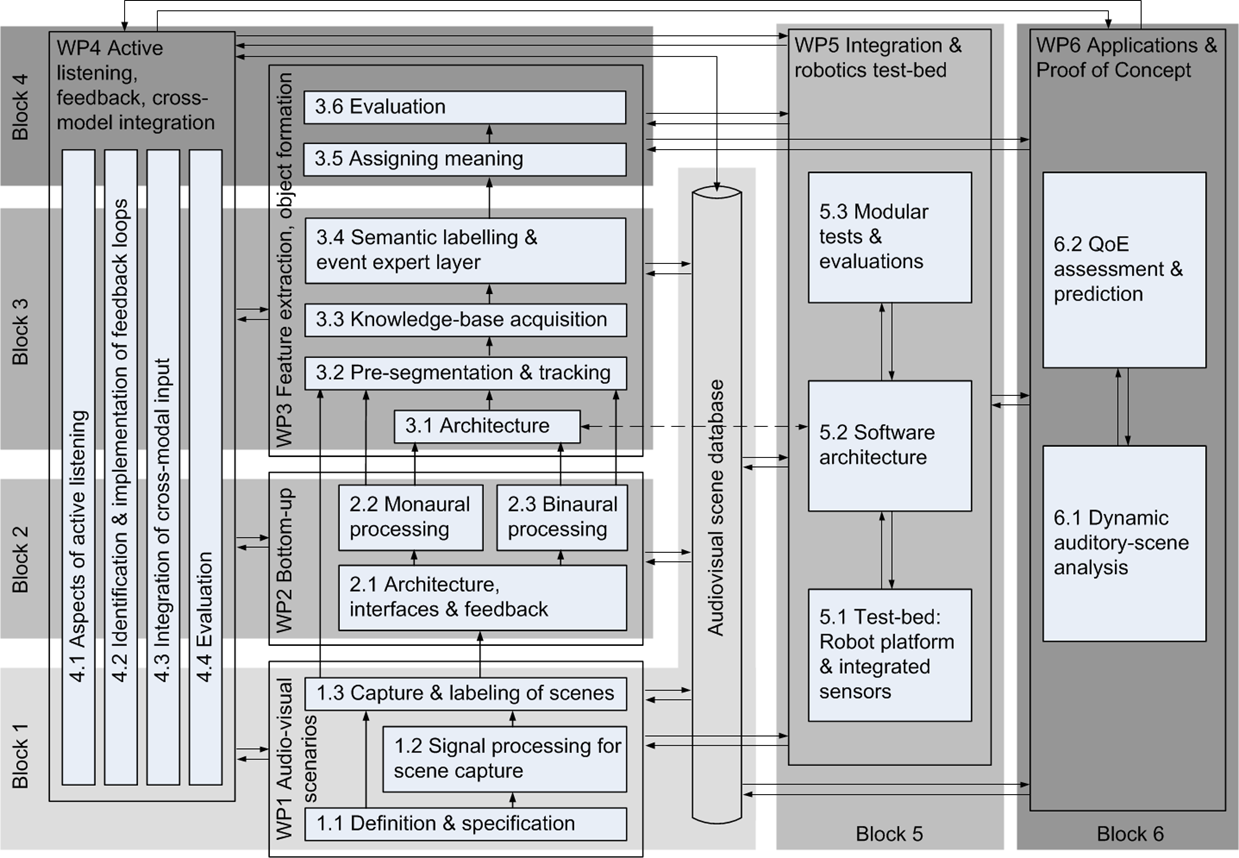
Operational structure and interdependencies of the six technical work packages within Two!Ears. With the modular structure of the system the risk of bottlenecks can be reduced, since system-blocks such as WP6’s applications can be addressed based on different intermediate versions of the system, e.g. independent of the robot platform.
Impact
Two!Ears targets visionary research on advanced computational models of human audition. The project is interdisciplinary in several ways, and tries to put into practice what has been portrayed as the way to follow in audition modelling, namely, to include cognition and the extraction of meaning, and the active way in which humans explore their environment. Given the overall strong role of sound in our modern society – including both positive aspects, like communication, sound design, sound scape generation, and negative aspects such as noise impact, stress and hearing damage – it is of great practical value to have automatic tools for the analysis and evaluation of sound-related effects. Our scientific approach and dissemination strategy ensures that the ambitious goals will lead to results that have breakthrough character and show strong impact on science, technology and society.
The following is a list of key-features of the project:
- Human-centeredness
- Toolbox of evaluated modules
- Active Hearing
- Cross-modal integration
- Meaning extraction and awareness
- Exploration & top-down adaptation
- Public model software & audiovisual scene database